
简介
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于
大数据实时处理领域。
消息队列
- 消息队列―-用于存放消启的组件
- 程序员可以将消息放入到队列中,也可以从消息队列中获取消息
- 很多时候消息队列在是一个永久性的存储,是作为临时存储存在的(设定一个期限:设置消息在MQ中保存10天)
- 消息队列中间件:Kafka、Active MQ、RabbitMQ、RocketMQ、ZeroMQ
场景
消息队列中间件就是用来存储消息的软件(组件)。举个例子来理解,为了分析网站的用户行为,我们需要记录用户的访问日志。这些一条条的日志,可以看成是一条条的消息,我们可以将它们保存到消息队列中。将来有一些应用程序需要处理这些日志,就可以随时将这些消息取出来处理。
异步处理
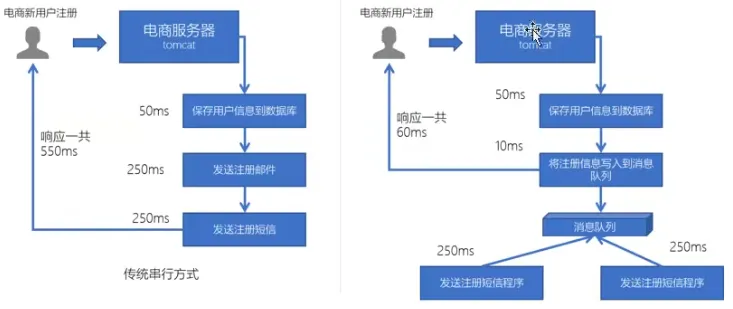
系统解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
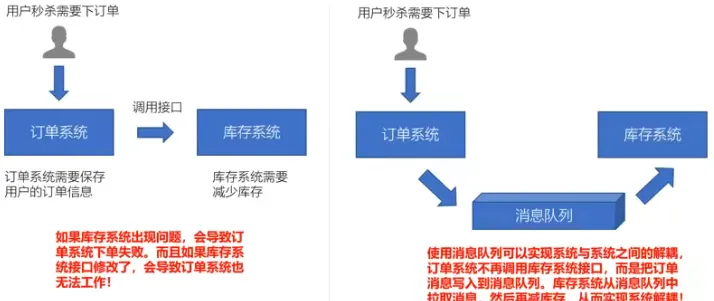
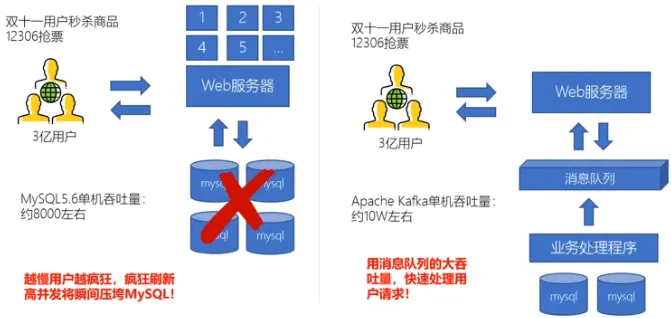
流量削峰
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
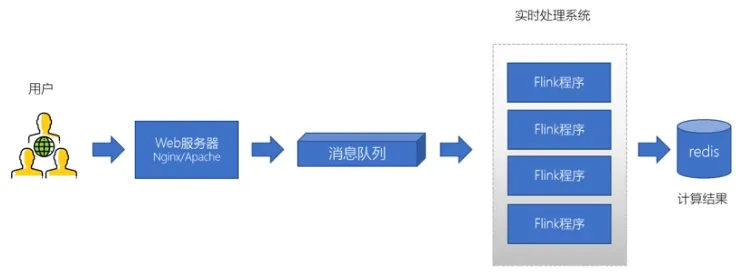
日志处理
flume -> kafka -> fink -> redis
比如抖音实时推荐、滴滴路线分析
消息队列两种模式
- 点对点模式
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
- 发布 / 订阅模式 (一对多模式)观察者模式(Observer)
- 定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新。
- 一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知。
- 消息生产者(发布)将消息发布到 topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。有两种模式:
(1)消费者主动拉取数据
需要自己去轮询,没有消息的时候CPU也会空转
(2)生产者主动推送数据
如果消费者处理能力达不到,会宕机,也可能有消费者资源浪费
Kafka架构
Broker
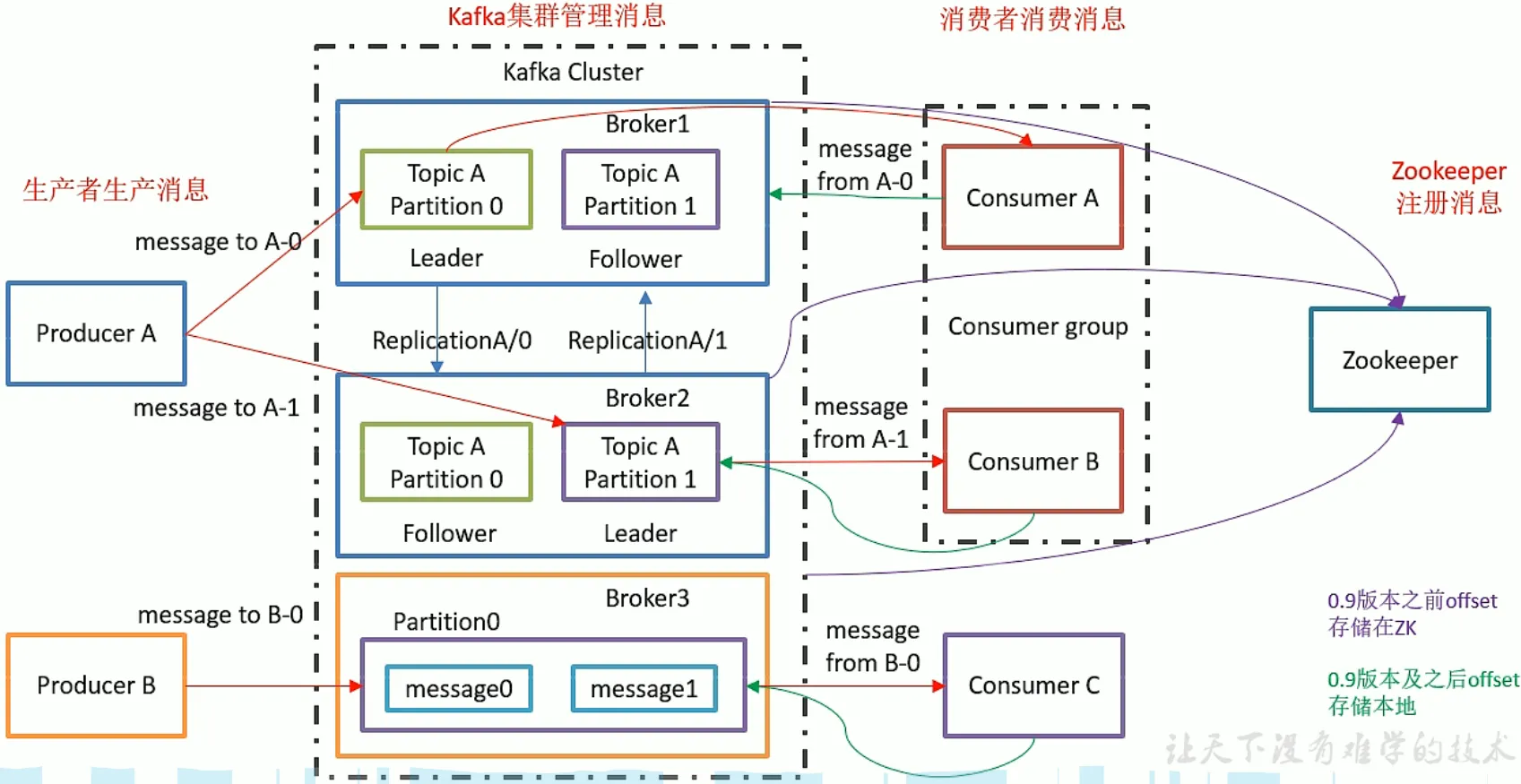
Kafka 集群包含一个或多个服务器,服务器节点称为 broker
Topic
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic
- 物理上不同Topic的消息分开存储
- 逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
- topic中的数据分割为一个或多个partition。
- 每个topic至少有一个partition,当生产者产生数据的时候,根据分配策略,选择分区,然后将消息追加到指定的分区的末尾(队列)
- 为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
Leader
每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower。
Follwer
每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对 象都是 leader。
Replication
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。
Producer
消息生产者,就是向 kafka broker 发消息的客户端;
Consumer
消息消费者,向 kafka broker 取消息的客户端
Consumer Group
消费者组,由多个 consumer 组成。消费者组内每个消费者负 责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所 有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
生产者、消费者模型
- 通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯

- 数据传递流程
- 生产者消费者模式,即N个线程进行生产,同时N个线程进行消费,两种角色通过内存缓冲区进行通信
- 生产者负责向缓冲区里面添加数据单元
- 消费者负责从缓冲区里面取出数据单元
- —般遵循先进先出的原则
缓冲区
- 解耦:
- 假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖
- 支持并发
- 生产者直接调用消费者的某个方法过程中函数调用是同步的
- 万一消费者处理数据很慢,生产者就会白白糟蹋大好时光
- 支持忙闲不均
- 缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。
- 当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。
- 等生产者的制造速度慢下来,消费者再慢慢处理掉。
数据单元
- 关联到业务对象
- 数据单元必须关联到某种业务对象
- 完整性
- 就是在传输过程中,要保证该数据单元的完整
- 独立性
- 就是各个数据单元之间没有互相依赖
- 某个数据单元传输失败不应该影响已经完成传输的单元;也不应该影响尚未传输的单元。
- 颗粒度
- 数据单元需要关联到某种业务对象。那么数据单元和业务对象应该处于的关系(一对一?一对多)
- 如果颗粒度过小会增加数据传输的次数
- 如果颗粒度过大会增加单个数据传输的时间,影响后期消费
命令
# topic list
kafka-topics.sh --zookeeper slave:2181 --list
# topic create
kafka-topics.sh --zookeeper slave:2181 --create --replication-factor 3 --partitions 1 --topic first
# topic delete
kafka-topics.sh --zookeeper slave:2181 --delte --topic first
# topic desc
kafka-topics.sh --zookeeper slave:2181 --desc --listkafka-console-producer.sh --topic first --broker-list slave:9092
# --from-beginning 从一开始读取
kafka-console-consumer.sh --topic first --bootsrap-server slave:9092 --from-beginning