
基础
MySQL 基础架构
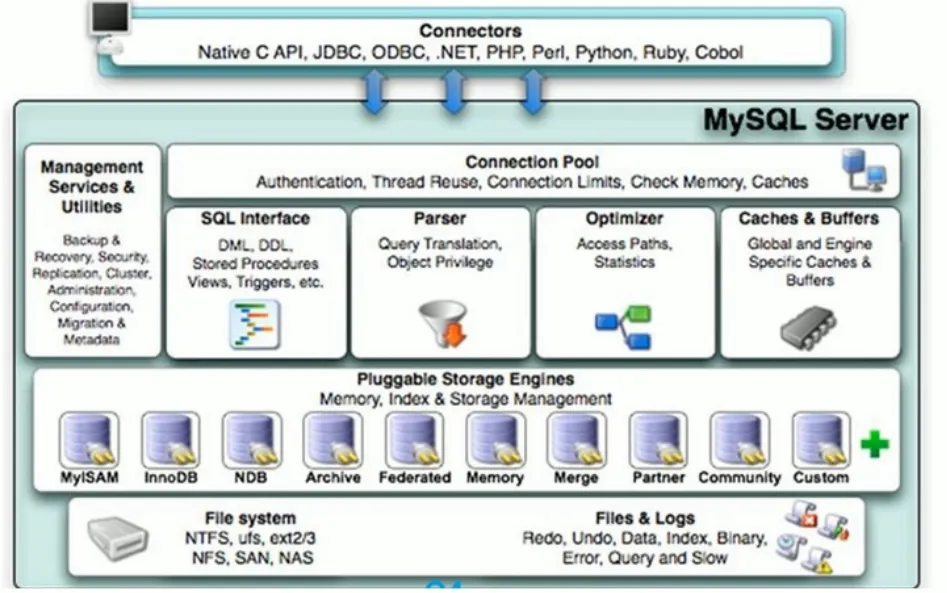
- 连接层
- 服务层
- 引擎层
- 存储层
SQL 类型
DML
data manipulation language
SELECT UPDATE INSERT DELETE
DDL
data definition language
CREATE ALTER DROP
DCL
Data Control Language
grant deny revoke
SQL执行流程
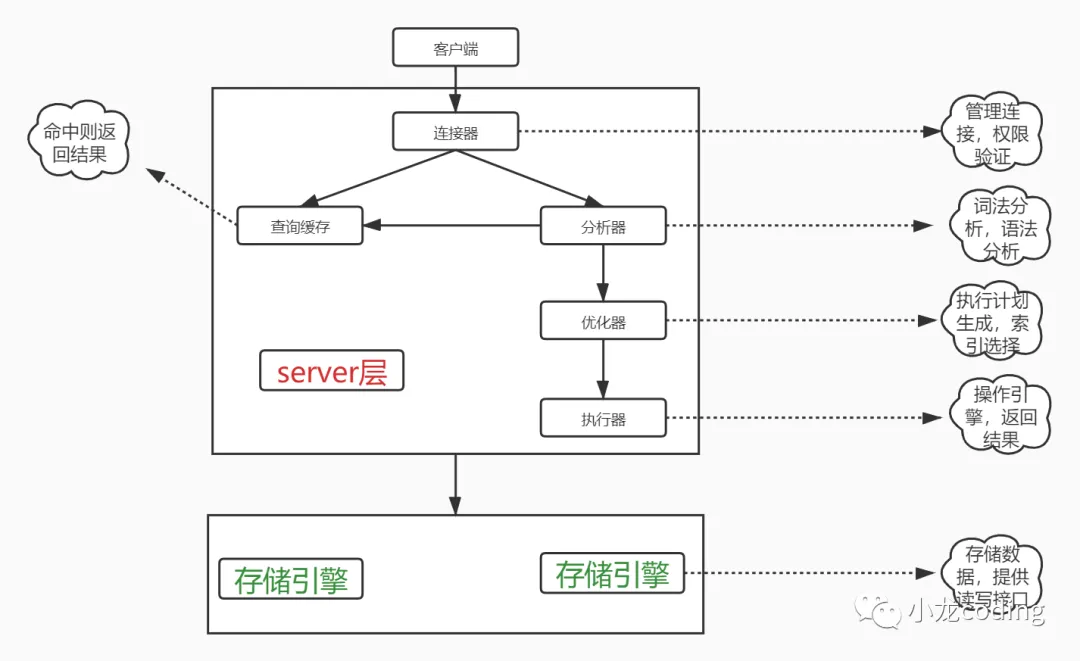
mysql分为server层与存储引擎层,server层包含连接器、分析器、优化器、执行器。
接下来以一条sql查询语句执行过程介绍各个部分功能。客户端执行一条sql:
- 首先由连接器进行身份验证,权限管理
- 若开启了缓存,会检查缓存是否有该sql对应结果(缓存存储形式key-vlaue,key是执行的sql,value是对应的值)若开启缓存又有该sql的映射,将结果直接返回;
- 分析器进行词法语法分析
- 优化器会生成执行计划、选择索引等操作,选取最优执行方案
- 然后来到执行器,打开表调用存储引擎接口,逐行判断是否满足查询条件,满足放到结果集,最终返回给客户端;若用到索引,筛选行也会根据索引筛选。
存储引擎
- 查看数据库引擎
shell
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+- 查看系统默认存储引擎
- 对比
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | NO | YES |
| 事务 | NO | YES |
| 行表锁 | 表锁,不适合高并发 | 行锁,操作时只锁某一行,适合高并发 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还缓存真实数据,对内存要求比较高,而且内存大小对性能有决定性影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | YES | YES |
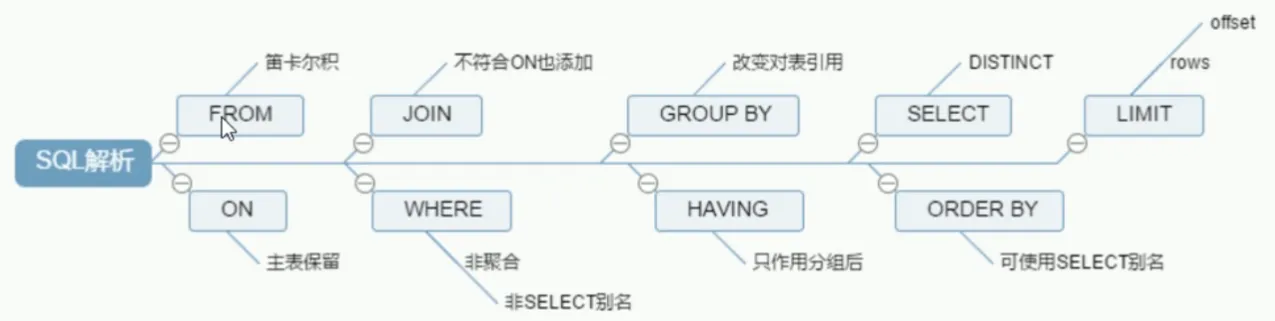
SQL执行加载顺序
sql
select * from tb where a=1;先 from 在 on join,在 where group by,最后进行 select ,然后 order by limit
范式
第一范式:字段具有原子性,不可再分(字段单一职责)
第二范式:满足第一范式,每行应该被唯一区分,加一列存放每行的唯一标识符,称为主键(都要依赖主键)
第三范式:满足一二范式,且一个表不能包含其他表已存在的非主键信息(不间接依赖-不存在其他表的非主键信息)
范式优点与缺点:
优点:范式化,重复冗余数据少,更新快,修改少,查询时更少的distinct
缺点:因为一个表不存在冗余重复数据,查询可能造成很多关联,效率变低,可能使一些索引策略无效,范式化将列存在不同表中,这些列若在同一个表中可以是一个索引