
基础
事物
支持事务, Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
命令
- setnx key value:只在 key 不存在的时候将值设为 value
分布式锁
- redisson
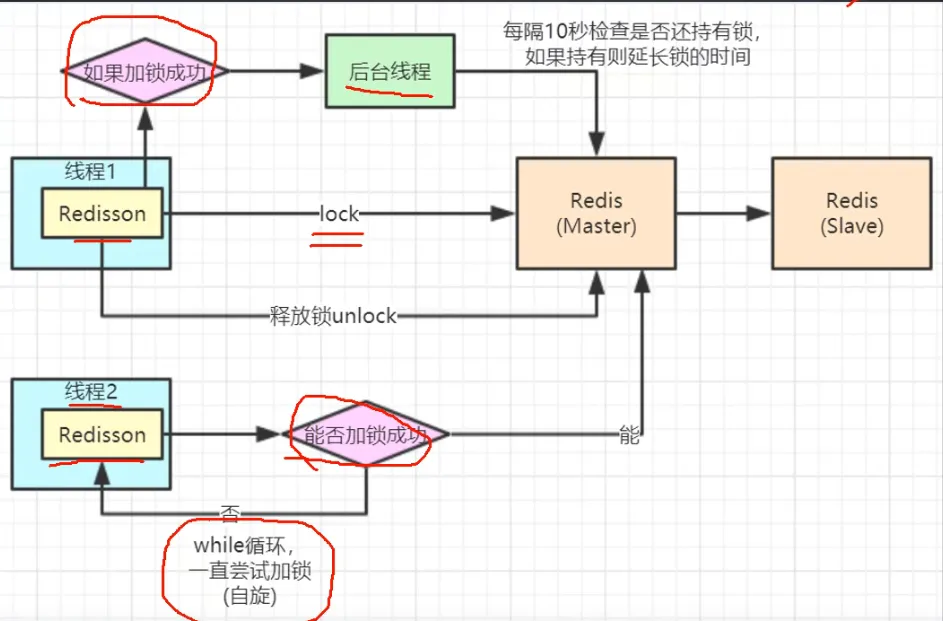
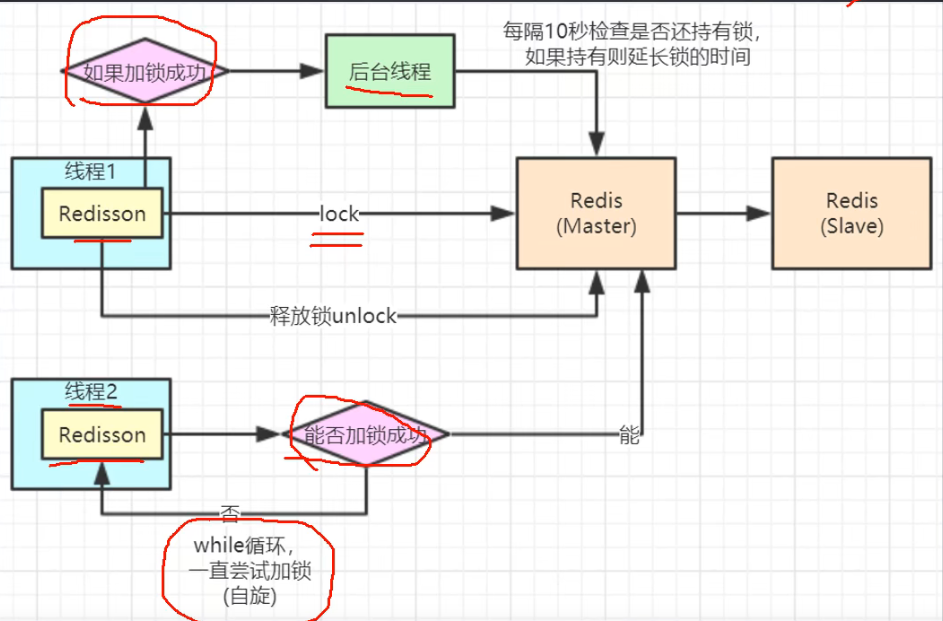
优化:
- 分段锁:Hash 运算 分段锁,或者商品id锁
存在问题:
- 主从架构可能会存在主节点数据未同步从节点导致锁重复
- redlock
- zookeeper:CP一致性 数据同步时会段时间不可用
缓存淘汰
内存是有限的,如果有新的 key 进入内存不够,则需要淘汰部分缓存
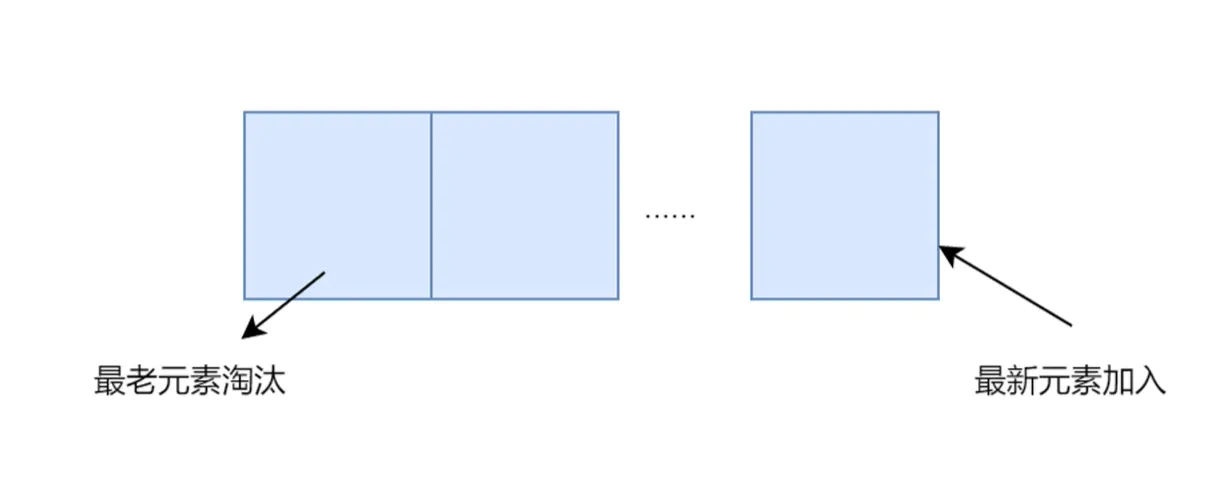
FIF0:先进先出,淘汰最先进入缓存的数据
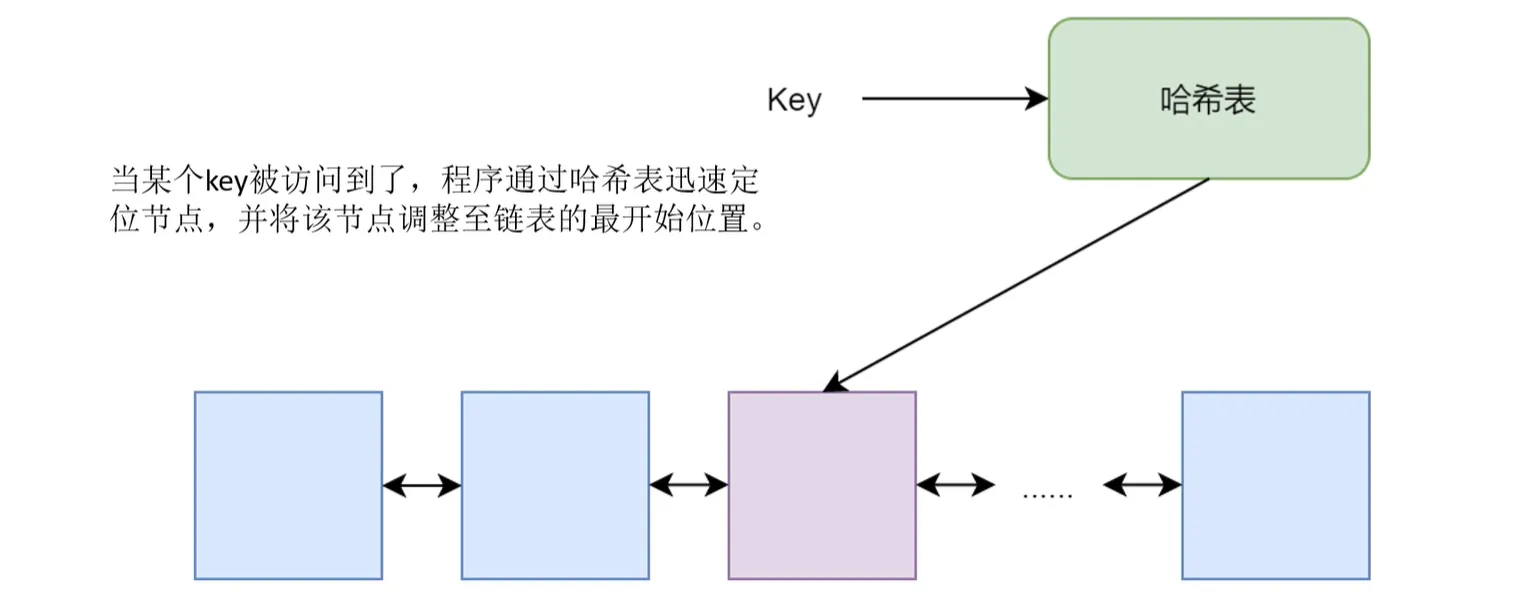
LRU:最近最少未使用
- LRU实现方法,这里给出其中一种实现思路:双向链表+哈希表的形式存储。
- 双向链表用于组织数据,数据采用链表节点进行组织,最经常访问的排在前面,哈希表用于存储键key和值链表节点
- 每次访问都会被移动也会浪费性能,所以引入 LRU-K
- LFU:最近不经常使用

过期删除
- 主动删除:设置删除间隔时间,在指定时间后进行主动删除工作
- 优点:易于理解,设置合理的间隔后不会使内存占用超标
- 缺点:当 Redis 比较忙时,设置删除时间碰巧到期了,主动删除会额外增加 Redis 负担。
- 惰性删除:当用到这个缓存,在检测它的过期时间,程序取值时查看该数据是否已经过期,如果没过期,则返回,如果过期,则删除
- 优点:服务器运算资源占用小
- 缺点:容易造成某些数据长期霸占在内存中,不被删除的情况。
- 定期删除=主动删除+惰性删除
- 每隔一段时间,跑主动删除,不跑主动删除时,执行惰性删除策略。
缓存一致
Cache Aside 的核心思想就是,当缓存的数据有更新值了,它采用的不是更新缓存数据,而是删除缓存数据
保证最终一致性
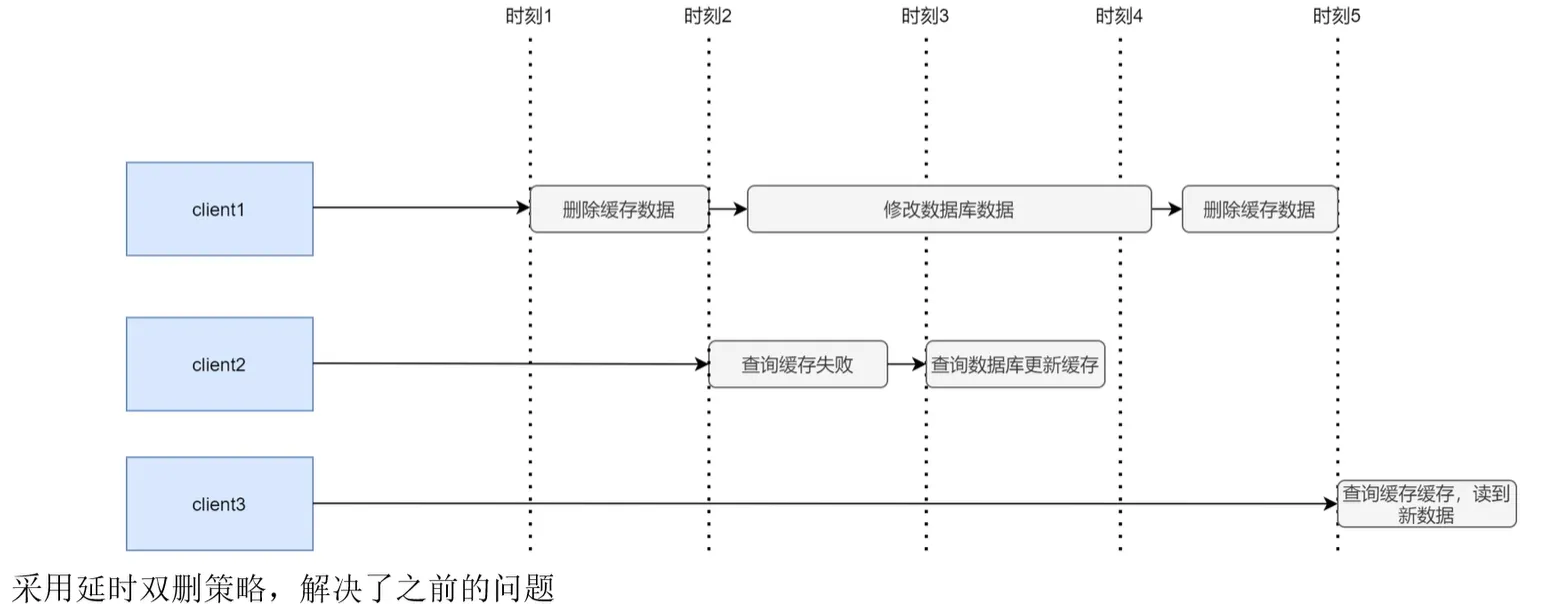
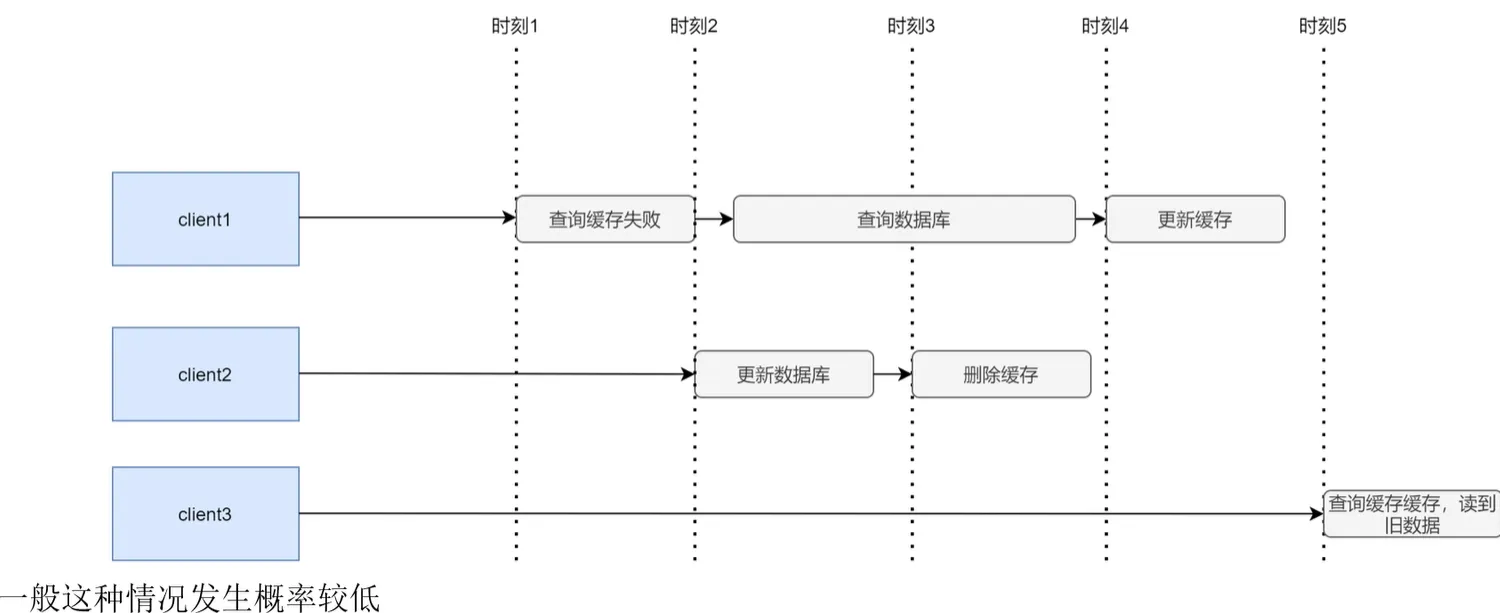
- 先删除在更新数据,但是这样其它线程如果速度足够快还是会读到脏数据,这个时候可以采用延迟双侧删除策略
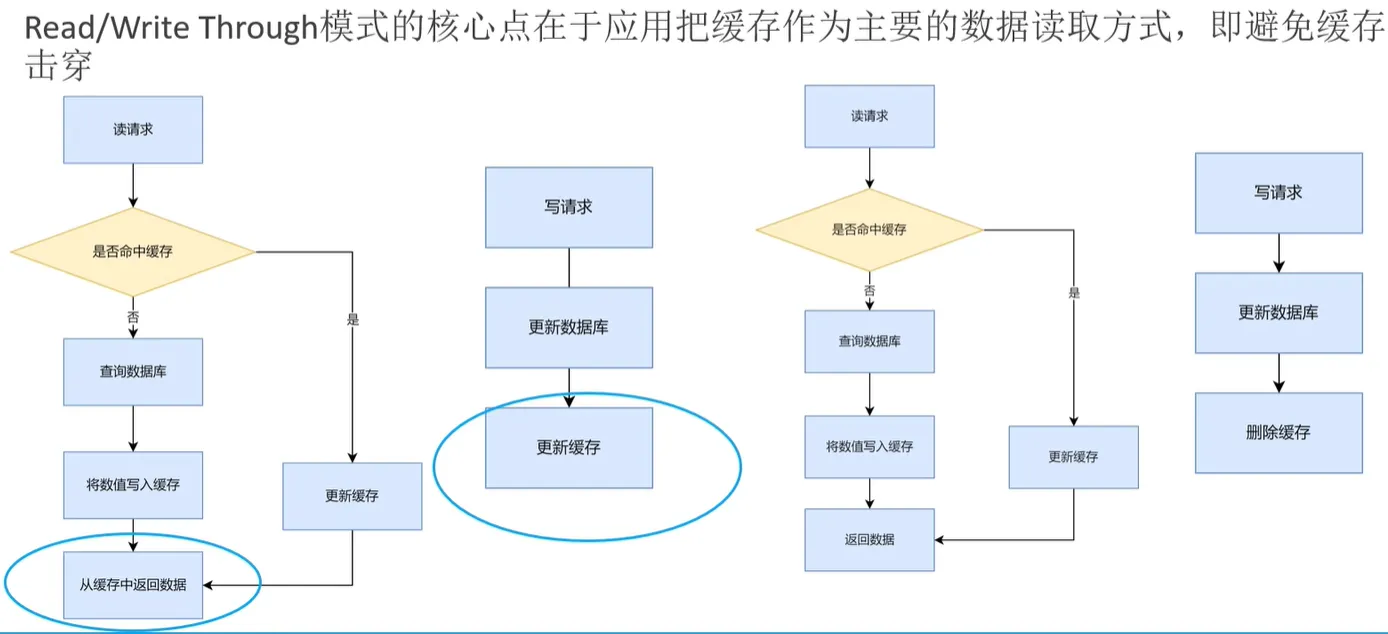
- Read/Wite Through
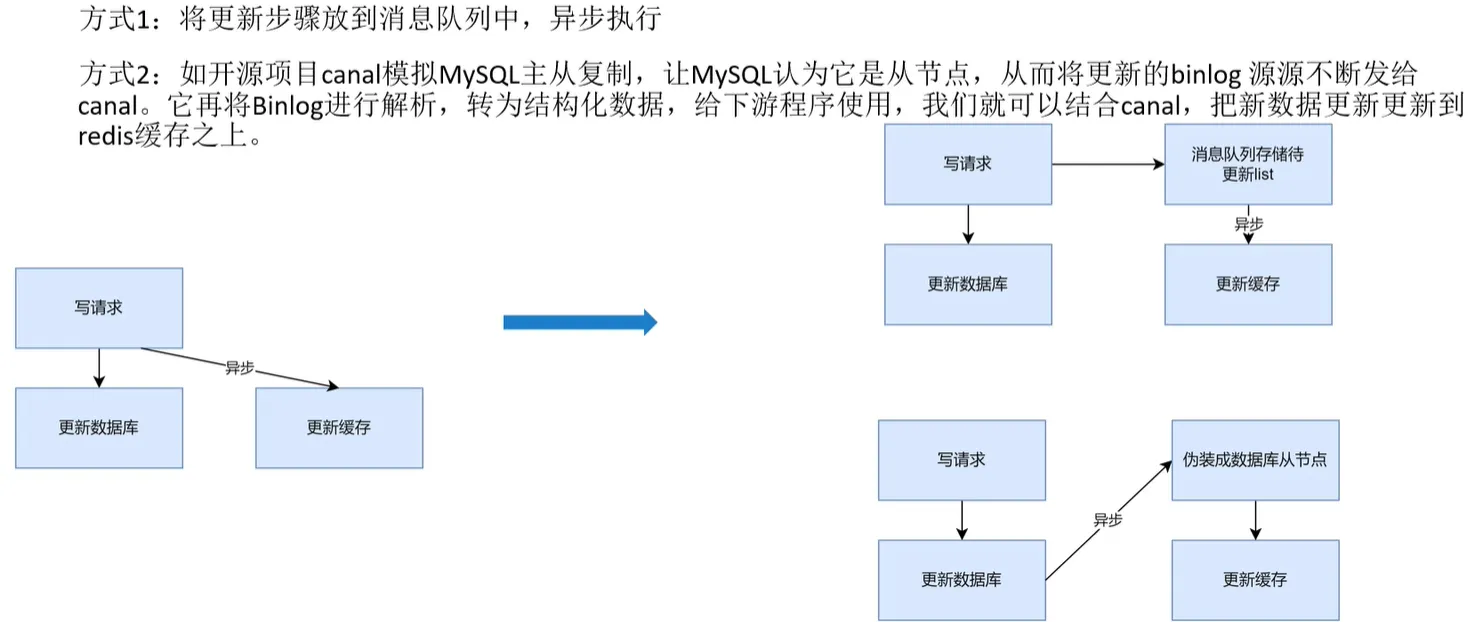
- Writer behind
缓存击穿
查询某个数据的值,该值在缓存中无,在数据库中有
- 一般缓存都会设置个数据过期时间,所以缓存击穿的情况比较常见
- 缓存击穿带来的问题:如果对该值查询突然特别大,由于缓存中无该数据,所以请求就会打到后端数据库上
- 处理
- 从MySQL角度出发:减少击穿后的直接流量
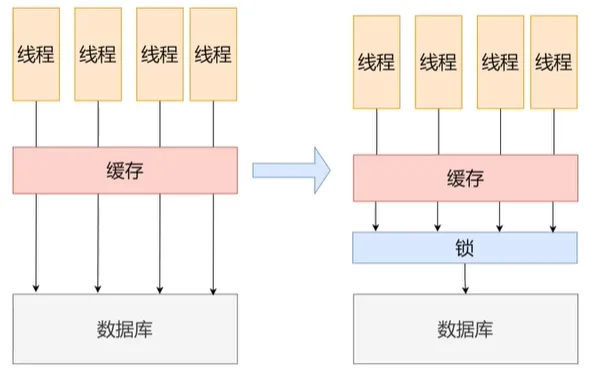
- 从Redis角度出发:
- 设置热点数据永不过期
- 热点数据后台启动一个异步线程,重新把数据回填缓存层
缓存穿透
查询一个数据库也不存在的数据,即缓存查不到,数据库也查不到所以透了
- 拦截非法查询请求
- 缓存空对象
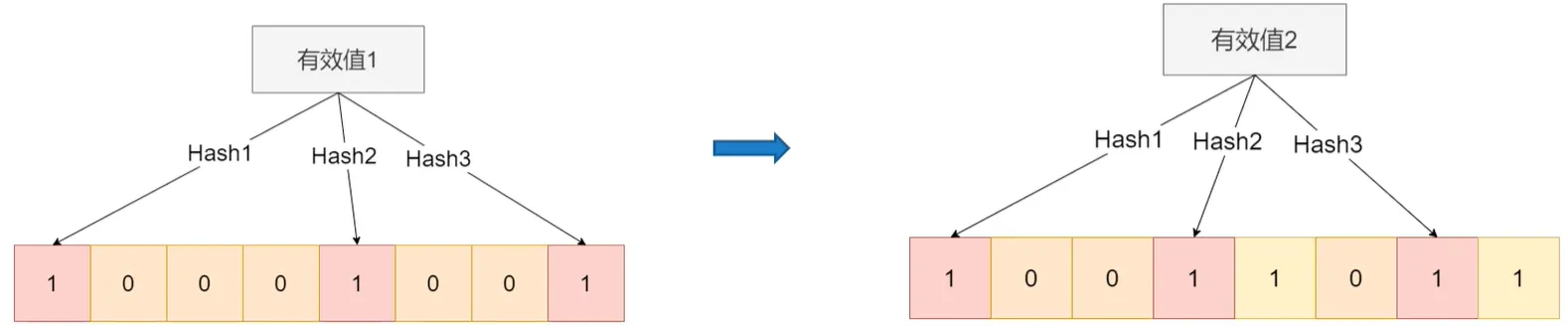
- 布隆过滤器
- 设计思路:设计k个hash映射函数,这k个映射函数各不相同,把在数据库中的有效数据通过这个映射函数得到数组指定位置,并置为1
- 查询思路:输入查询数据,通过这一系列hash函数,判断对应位置是否全为1。如果是,则很大概率就是我们的有效请求了,如果有一位为0,则该查询一定是无效查询
- 提前查询数据库做一个布隆表
缓存雪崩
一大批被缓存的数据,同时失效,此时对于这一批的数据请求就全打到数据库上,导致数据库宕机
和缓存击穿类似
- 从MySQL角度出发
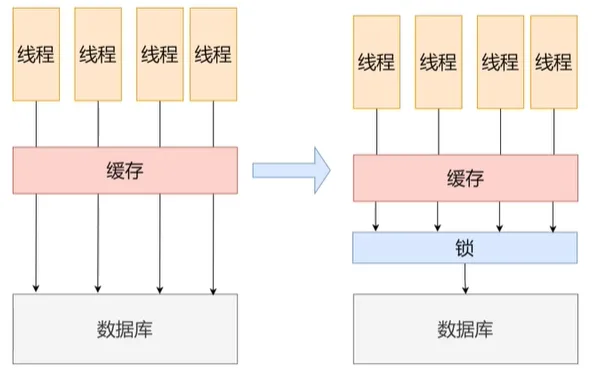
- redis
- 设置热点数据永不过期
- 分析失效时间,尽量让失效时间点分散
- 缓存预热,即在上线前,根据当天的情况分析,将热数据直接加载到缓存系统